비트코인이 가진 성격에 대해 다양한 의견이 존재한다. 결제 수단으로써의 비트코인, 디지털 금과 같은 가치저장 수단, 기술주와 같은 위험 자산 등등...
이번 포스팅에서는 비트코인의 가격과 금 가격, 주가와의 상관관계를 통해 비트코인의 자산으로써의 성격을 알아보고자 한다.
※ 사전 준비
야후 파이낸스(yfinance) install 및 import 완료
판다스(pandas) import 완료
btc = yf.download('BTC-USD', period = '2y', auto_adjust = True)

비트코인 가격, 금(선물) 가격, 나스닥 지수, S&P500 지수 데이터 2년치를 추출했다.
배당, 액면분할 등을 고려하기 위해 수정주가로 산출했다. (auto_adjust = True)
※ 야후 파이낸스에서 데이터를 가져오는 내용을 자세히 보고 싶다면, 이 포스팅을 참고
(2021.07.10 - [Quant] - 파이썬, 구글 코랩 / 야후 파이낸스로 주가 데이터 추출)
# 비트코인, 금, 나스닥, S&P500 데이터 추출
btc = yf.download('BTC-USD', period = '2y', auto_adjust = True)
gold = yf.download('GC=F', period = '2y', auto_adjust = True)
nasdaq = yf.download('^IXIC', period = '2y', auto_adjust = True)
snp500 = yf.download('^GSPC', period = '2y', auto_adjust = True)

비트코인과 금 데이터는 위와 같다.
비트코인은 731개 행, 금은 505행의 데이터가 존재한다.
비트코인은 24/7 계속 거래되기 때문에 데이터의 양이 더 많다.

나스닥, S&P500 데이터는 위와 같다.
둘 다 504개 행의 데이터가 존재한다.
금 선물 데이터보다 1개 더 적은데, 이유는 잘 모르겠다. (선물거래소보다 증권거래소 휴장일이 하루 더 많은 듯...)
btc = pd.DataFrame(btc['Close'])

기존 데이터프레임에서 종가 데이터만 추출한다.
코드를 설명하자면, btc라는 데이터프레임의 ['Close']라는 행을 가져오고,
이를 다시 데이터프레임으로 만들어 btc에 할당하라는 뜻이다.
# 비트코인, 금, 나스닥, S&P 500 종가 데이터 추출
btc = pd.DataFrame(btc['Close'])
gold = pd.DataFrame(gold['Close'])
nasdaq = pd.DataFrame(nasdaq['Close'])
snp500 = pd.DataFrame(snp500['Close'])
위와 같이 종가 데이터만 남았다.
금, 나스닥, S&P500 모두 동일하다
btc.reset_index(inplace = True)

데이터를 보면 인덱스가 날짜로 되어 있다.
개별 자산별로 날짜 형식이 동일하면 좋겠지만, 다른 관계로 년월일만 남기고 나머지는 제거해줄 생각이다.
이를 위해, 날짜로 설정된 인덱스를 재설정한다.
# 인덱스 재설정
btc.reset_index(inplace = True)
gold.reset_index(inplace = True)
nasdaq.reset_index(inplace = True)
snp500.reset_index(inplace = True)
위와 같이 날짜에 설정되어 있던 인덱스가 해제되었고, 새로운 인덱스가 만들어졌다.
btc['Date'] = btc['Date'].astype('str')
btc['Date'] = btc['Date'].str.slice(0, 10)

날짜 데이터를 년월일(yyyy-mm-dd)만 남기기 위해 문자열(String) 타입으로 전환한다.
astype은 데이터의 형식을 전환하기 위해 사용하는 메소드이다.
그리고 slice(start, end)는 왼쪽부터 시작 인덱스(start)부터 끝 인덱스(end)까지 남기는 것을 뜻한다.
단, 끝 인덱스(end)는 포함하지 않는다.
예를 들어, tistory라는 글자가 있을 때 sto만 남기고 싶다면, slice(2, 5)가 되는 것이다.
다시 돌아가서, yyyy-mm-dd(- 포함)의 글자 수가 10개이기 때문에, 앞에서 10번째 글자까지만 남긴다.
# 년월일만 남기기
# 스트링으로 전환
btc['Date'] = btc['Date'].astype('str')
gold['Date'] = gold['Date'].astype('str')
nasdaq['Date'] = nasdaq['Date'].astype('str')
snp500['Date'] = snp500['Date'].astype('str')
# 앞의 10글자만 남기기
btc['Date'] = btc['Date'].str.slice(0, 10)
gold['Date'] = gold['Date'].str.slice(0, 10)
nasdaq['Date'] = nasdaq['Date'].str.slice(0, 10)
snp500['Date'] = snp500['Date'].str.slice(0, 10)

btc.rename(columns = {'Close':"btc_price"}, inplace = True)
df = pd.merge(btc, gold, on = 'Date')

4개의 데이터프레임으로 되어 있는 데이터들을 하나의 데이터프레임으로 모아준다.
그 전에, 개별 데이터의 행 이름이 'Close'로 동일하기 때문에, 구분을 위해 행 이름을 변경해준다.
행 이름을 변경한 후, merge() 메소드를 통해 각각의 데이터프레임을 병합한다.
기준은 날짜로 지정하였고, 이 경우 날짜가 동일한 데이터는 병합되고, 동일한 날짜가 없는 데이터는 버려진다.
# 하나의 데이터프레임으로 합침
# 행 이름 변경
btc.rename(columns = {'Close':"btc_price"}, inplace = True)
gold.rename(columns = {'Close':"gold_price"}, inplace = True)
nasdaq.rename(columns = {'Close':"nasdaq_price"}, inplace = True)
snp500.rename(columns = {'Close':"snp500_price"}, inplace = True)
# 각각의 데이터프레임 병합
df = pd.merge(btc, gold, on = 'Date')
df = pd.merge(df, nasdaq, on = 'Date')
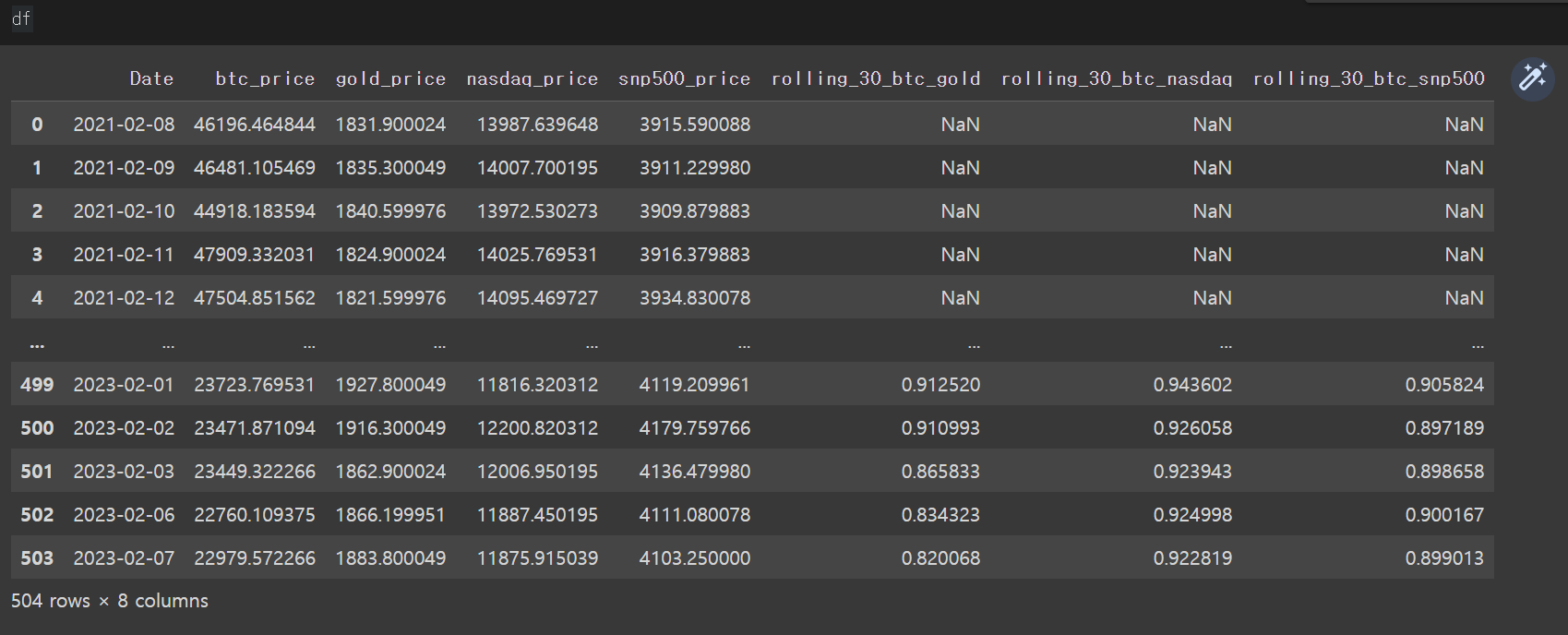
df = pd.merge(df, snp500, on = 'Date')위의 코드를 실행한 결과는 아래와 같다.
행의 개수가 기존 4개 데이터프레임의 최소값인 504개로 줄었으며, 개별 종가데이터가 하나의 데이터프레임으로 합쳐졌다.

df['rolling_30_btc_gold'] = df['btc_price'].rolling(30).corr(df['gold_price'])

다음은 상관계수를 구할 차례이다.
판다스에서는 rolling()과 corr()메소드를 가지고 있기 때문에, 데이터프레임에서 바로 구할 수 있다.
rolling(window)은 이동평균, 이동 상관계수 등을 구할 때 자주 사용하는 메소드로, 숫자에 해당하는 행만큼을 한 구역(window)로 묶고 평균, 상관관계 등을 계산할 수 있게끔 해준다.
예를 들어, window = 5라 하면 아래의 빨간 사각형(?)이 설정되는 것이다.
그러므로, rolling(30).corr()은 30개 행의 구역의 상관계수를 구하라는 뜻이 된다.

# 상관계수 구하기
df['rolling_30_btc_gold'] = df['btc_price'].rolling(30).corr(df['gold_price'])
df['rolling_30_btc_nasdaq'] = df['btc_price'].rolling(30).corr(df['nasdaq_price'])
df['rolling_30_btc_snp500'] = df['btc_price'].rolling(30).corr(df['snp500_price'])위의 코드를 실행한 결과는 아래와 같다.
보기 쉽게, 그래프로 그리면 아래와 같다.
최신 데이터를 보면, 각각의 상관계수가 0.9에 육박하는 것을 볼 수 있는데,
이를 해석하면 "최근에는 비트코인, 금, 나스닥, s&p500의 가격이 대체로 같이 움직인다"는 뜻이다.
인플레이션 추세가 조금 꺾이고, 연준의 긴축 기조 전환에 대한 기대감으로 대부분의 자산 가격이 상승하고 있는 최근 동향을 반영해주는 결과인 듯하다.

전체 코드
!pip install yfinance
import yfinance as yf
import pandas as pd
# 비트코인, 금, 나스닥, S&P500 데이터 추출
btc = yf.download('BTC-USD', period = '2y', auto_adjust = True)
gold = yf.download('GC=F', period = '2y', auto_adjust = True)
nasdaq = yf.download('^IXIC', period = '2y', auto_adjust = True)
snp500 = yf.download('^GSPC', period = '2y', auto_adjust = True)
# 비트코인, 금, 나스닥, S&P 500 종가 데이터 추출
btc = pd.DataFrame(btc['Close'])
gold = pd.DataFrame(gold['Close'])
nasdaq = pd.DataFrame(nasdaq['Close'])
snp500 = pd.DataFrame(snp500['Close'])
# 인덱스 재설정
btc.reset_index(inplace = True)
gold.reset_index(inplace = True)
nasdaq.reset_index(inplace = True)
snp500.reset_index(inplace = True)
# 년월일만 남기기
# 스트링으로 전환
btc['Date'] = btc['Date'].astype('str')
gold['Date'] = gold['Date'].astype('str')
nasdaq['Date'] = nasdaq['Date'].astype('str')
snp500['Date'] = snp500['Date'].astype('str')
# 앞의 10글자만 남기기
btc['Date'] = btc['Date'].str.slice(0, 10)
gold['Date'] = gold['Date'].str.slice(0, 10)
nasdaq['Date'] = nasdaq['Date'].str.slice(0, 10)
snp500['Date'] = snp500['Date'].str.slice(0, 10)
# 하나의 데이터프레임으로 합침
# 행 이름 변경
btc.rename(columns = {'Close':"btc_price"}, inplace = True)
gold.rename(columns = {'Close':"gold_price"}, inplace = True)
nasdaq.rename(columns = {'Close':"nasdaq_price"}, inplace = True)
snp500.rename(columns = {'Close':"snp500_price"}, inplace = True)
# 각각의 데이터프레임 병합
df = pd.merge(btc, gold, on = 'Date')
df = pd.merge(df, nasdaq, on = 'Date')
df = pd.merge(df, snp500, on = 'Date')
# 상관계수 구하기
df['rolling_30_btc_gold'] = df['btc_price'].rolling(30).corr(df['gold_price'])
df['rolling_30_btc_nasdaq'] = df['btc_price'].rolling(30).corr(df['nasdaq_price'])
df['rolling_30_btc_snp500'] = df['btc_price'].rolling(30).corr(df['snp500_price'])
# 시각화
import matplotlib.pyplot as plt
df.plot(x = 'Date', y=['rolling_30_btc_gold', 'rolling_30_btc_nasdaq', 'rolling_30_btc_snp500'])




댓글